Collectd — это очень лёгкий и производительный сервис для сбора различной статистики о системе. Благодаря огромному количеству плагинов и возможности создавать свои, вы можете собирать информацию обо всём, что происходит в системе, начиная загрузкой процессора, оперативной памяти и доступного места на диске, заканчивая количеством активных запросов в Nginx, активных соединений с MySQL и других подобных параметров.
Программа только сохраняет данные, для их хранения можно использовать плагины вывода. Вывод поддерживается в StatsD, InfluxDB, MongoDb, Redis а также можно отправлять эти данные другому сервису Collectd или просто сохранять в CSV-файл. В этой статье мы будем использовать InfluxDB для хранения данных и Grafana для их удобного отображения.
Установка CollectD
Для установки CollectD в операционной системе CentOS 7 сначала необходимо подключить репозиторий EPEL. Для этого выполните:
yum install epel-release
Затем установите саму программу:
yum install collectd
Для установки CollectD в Ubuntu используйте такую команду:
sudo apt install collectd
Теперь можно переходить к настройке программы.
Настройка Collectd
Начнём с конфигурационного файла. Он находится по адресу /etc/collectd.conf. В начале файла идут параметры, которые определяют общие настройки работы плагинов. Рассмотрим основные из них:
- Hostname — имя хоста, которое будет сохранятся в каждой записи метрики от этого сервиса;
- FQDNLookup — нужно ли использовать DNS для разрешения доменных имён;
- BaseDir — основная папка программы, где расположены её файлы;
- PIDFile — путь к PID-файлу программы;
- PluginDir — папка с плагинами для программы;
- TypesDB — типы полей по умолчанию, которые используются в стандартных плагинах Collectd.
- AutoLoadPlugin — автоматическая загрузка плагинов, установите значение этого параметра в true, чтобы все сконфигурированные плагины загружались автоматически;
- Interval — интервал сбора данных, обычно достаточно собирать данные раз в 30 секунд или раз в минуту.
- MaxReadInterval — максимальное время чтения данных из плагина;
- CollectInternalStats — собирать внутреннюю статистику Collectd, по умолчанию отключено;
- Timeout — количество попыток прочитать данные из плагина, перед тем, как будет записано пустое значение, по умолчанию 2;
- ReadThreads — количество потоков для чтения данных из плагинов;
- WriteThreads — количество потоков для записи данных.
Например, моя конфигурация выглядит вот так:

Давайте сначала заставим программу работать хоть как-то, а потом будем добавлять нужные плагины.
1. Настройка вывода данных
Как я уже сказал, у программы есть плагины для чтения и вывода данных. Чтобы сохранить полученные данные, нужно использовать плагин вывода. Вот список поддерживаемых плагинов:
- network
- unixsock
- graphte
- http
- kafka
- log
- mongodb
- redis
- redis
- riemann
- sensu
- tsdb
В этой статье я хочу использовать influxdb. Работать это будет с помощью плагина network. Мы будем подключаться к InfluxDb и отправлять ей данные. Для этого добавляем такую конфигурацию:
Здесь мы указываем сервер, на котором запущена InfluxDB, также можно указать порт, если он отличается от порта по умолчанию. Дальше перейдём к настройке InfluxDB. В конфигурационном файле /etc/influxdb/influxdb.conf найдите и расскоментируйте такие строки:
vi /etc/influxdb/influxdb.conf

Значение параметра bind-address менять не нужно, важно, чтобы этот порт остался именно таким, какой он есть, а если меняете порт, то его надо будет указывать в Collectd. В параметре database укажите желаемое имя базы данных, в typesdb пропишите такое же значение, как и для typesdb в файле collectd.conf. Затем перезапустите InfluxDB:
sudo systemctl restart influxdb
2. Плагин CPU
Для примера добавим данные о загрузке процессора с помощью плагина CPU. Для этого добавьте следующие строки в конфигурационный файл:
Вот значения этих параметров:
- ReportByState — выводить статистику для system, user, idle и других статусов;
- ReportByCpu — выводить статистику для каждого ядра cpu отдельно;
- ValuesPercentage — выводить значения в процентах.
Далее нужно перезапустить Collectd, чтобы применялись изменения:
sudo systemctl restart collectd
Затем нужно убедится, что данные поступают
USE база_данных;
SELECT * FROM cpu_value LIMIT 5
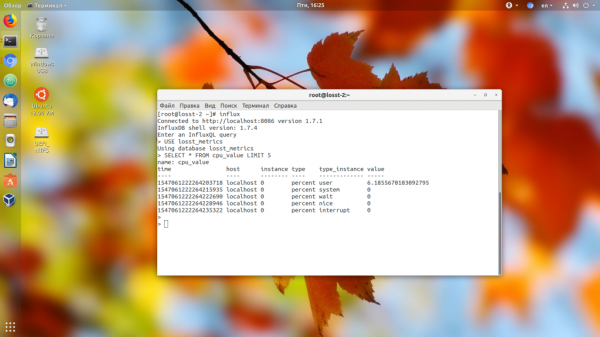
Если данные поступают, то вы увидите несколько строчек с данными. Значит всё хорошо, и можно переходить к настройке Grafana. Подробнее об этом я писал в статье установка и настройка Grafana. Например, настройки для вывода данных о загрузке процессора выглядят следующим образом:

В результате у вас может получиться вот такая панель статистики:

Вы можете посмотреть метрики collectd и с помощью других сервисов. А дальше давайте рассмотрим, как настраиваются отдельные плагины.
2. Плагин Memory
С помощью плагина Memory можно смотреть, сколько оперативной памяти свободно, а сколько занято под разные нужды. Для его активации добавьте:
Здесь первый параметр включает вывод данных в абсолютной величине, а второй в процентах.
3. Плагин df
С помощью плагина df вы можете узнать, сколько свободного места осталось на диске, а сколько места уже занято:
Здесь:
- Device — раздел диска, который мы хотим отслеживать;
- MountPoint — точка монтирования, о которой надо посмотреть информацию;
- ValuesPercentage — выводить значения в процентах.
4. Плагин load
Плагин load позволяет посмотреть текущую загрузку системы на основе файла /proc/loadavg:
5. Плагин nginx
Плагин nginx позволяет выводить статистику использования веб-сервера, которая доступа с помощью плагина stub_stats. Лучше всего для этих целей создать отдельный виртуальный хост Nginx, который будет слушать соединения только на локальном IP. Например:

Затем добавьте этот хост в плагин Collectd:
6. Плагин tail
Это самый интересный плагин, так как он позволяет читать любые файлы, например файлы логов, как команда терминала tail и на основе регулярных выражений выбирать из них метрики. В этом примере, мы будем читать файл лога nginx и посчитаем, сколько было кодов возврата 200, 300, 400 и 500. Конфигурация будет выглядеть вот так:
В параметре File мы указываем путь к лог файлу, который будем анализировать. Instanse — это имя разделителя, которое будет идентифицировать этот плагин.. Каждый блок Match содержит регулярное выражение, а также настройки поля, в которое будет записан результат. Каждый Match имеет свое поле Instanse, которое является именем поля, в которое будут записаны данные.
Type — это тип поля, но он применяется только во время фильтрации данных в Grafana или в другом инструменте, нужен, например, чтобы сохранить данные в процентах и байтах. Самый интересный параметр здесь — это DSType, он отвечает за то, как будут обрабатываться и сохраняться данные. Вот доступные типы:
- Gauge — подходит для тех параметров, которые нужно отображать как есть, без каких-либо изменений.
- Counter — подходит для параметров, которые нужно сравнивать с их предыдущим значением. Программа должна вычитать из текущего значения предыдущее. Значение параметра может только увеличиваться;
- Derive — работает аналогичным образом, только здесь значение может как увеличиваться, так и уменьшаться.
У каждого из параметров есть три варианта применения. Это Inc — сумма, Max — максимальное значение и Average — среднее значение. В примере я использовал GuageInc, так как мне нужно сохранить значение как есть.
Чтобы значения Derive и Counter адекватно отображались в Grafana, можно добавить к пункту SELECT функцию derivative из подменю transformation, тогда графики выглядят более наглядно. А когда мы видим просто прямую, уходящую под наклоном вверх, понять по ней что-то сложно.
7. Плагин MySQL
С помощью плагина mysql вы можете отслеживать статистику использования базы данных MySQL, например общий трафик к базе данных, количество select-, insert-, update-запросов и другие параметры. У него такая конфигурация:
Для работы этого плагина необходимо заполнить данные доступа к базе данных. Необходимо указать хост (Host), пользователя (User), пароль этого пользователя (Password), порт, на котором ожидает подключений сервис баз данных (Port). А также надо указать имя базы данных, статистику которой надо собирать.
8. Отправка данных по сети
Как я уже сказал, можно не только сохранять данные в разные хранилища с помощью плагинов, но и передавать их другому сервису Collectd для сохранения. Здесь используется плагин network. Чтобы включить сервер используйте такой код:
Здесь нужно указать IP-адрес, на котором сервер будет слушать соединения. Поскольку авторизацию мы отключили, лучше настроить iptables так, чтобы к нашему серверу мог подключится только нужный IP-адрес. А в конфигурации клиента достаточно добавить подключение к серверу:
Всё. Теперь данные будут передаваться на нужный нам сервер. После внесения любых изменений в конфигурацию необходимо перезапустить Collectd:
sudo systemctl restart collectd