Команда uniq предназначена для поиска одинаковых строк в массивах текста. При этом с найденными совпадениями пользователь может совершать множество действий — например, удалять их из вывода либо наоборот, выводить только их.
Работа команды осуществляется как с текстовыми файлами (в том числе, записями скриптов), так и с текстом, напечатанным в командной строке терминала.
Синтаксис uniq
Запись команды осуществляется следующим образом:
$ uniq опции файл_источник файл_для_записи
Файл источник указывает откуда надо читать данные, а файл для записи — куда писать результат. Но их указывать не обязательно. В примерах мы будем набирать текст, который нуждается в редактировании, прямо в командную строку терминала, воспользовавшись ещё одной командой — echo, и применив к ней опцию -e. Это будет выглядеть так:
echo -e [текст, слова в котором разделены управляющей последовательностью\n] | uniq
Эта управляющая последовательность нужна, чтобы указать утилите, что каждое слово выводится в новой строке. Если указано только название файла источника, результат выполнения команды появится прямо в окне терминала. А при наличии выходного файла текст будет напечатан в теле документа.
Опции uniq
У команды uniq есть такие основные опции:
- -u (—unique) — выводит исключительно те строки, у которых нет повторов.
- -d (—repeated) — если какая-либо строка повторяется несколько раз, она будет выведена лишь единожды.
- -D — выводит только повторяющиеся строки.
- —all-repeated[=МЕТОД] — то же самое, что и -D, но при использовании этой опции между группами из одинаковых строк при выводе будет отображаться пустая строка. [=МЕТОД] может иметь одно из трех значений — none (применяется по умолчанию), separate или prepend.
- —group[=МЕТОД] — выводит весь текст, при этом разделяя группы строк пустой строкой. [=МЕТОД] имеет значения separate (по умолчанию), prepend, append и both, среди которых нужно выбрать одно.
Вместе с основными опциями могут применяться дополнительные. Они нужны для более тонких настроек работы команды:
- -f (—skip-fields=N) — будет проведено сравнение полей, начиная с номера, который следует после указанного вместо буквы N. Поля — это слова, хотя, называть их словами в прямом смысле слова нельзя, ведь словом команда считает любую последовательность символов, отделенную от других последовательностей пробелом либо табуляцией.
- -i (—ignore-case) — при сравнении не будет иметь значение регистр, в котором напечатаны символы (строчные и заглавные буквы).
- -s (—skip-chars=N) — работает по аналогии с -f, однако, игнорирует определенное количество символов, а не строк.
- -c (—count) — в начале каждой строки выводит число, которое обозначает количество повторов.
- -z (—zero-terminated) — вместо символа новой строки при выводе будет использован разделитель строк NULL.
- -w (—check-chars=N) — указание на то, что нужно сравнивать только первые N символов в строках.
Примеры использования uniq
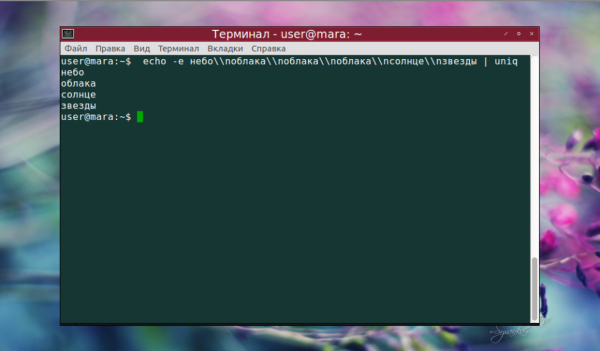
Прежде всего следует отметить главную особенность команды uniq — она сравнивает только строки, которые находятся рядом. То есть, если две строки, состоящие из одинакового набора символов, идут подряд, то они будут обнаружены, а если между ними расположена строка с отличающимся набором символов — то не будут поэтому перед сравнением желательно отсортировать строки с помощью sort. Без задействования файлов uniq работает так:
echo -e небо\nоблака\nоблака\nоблака\nсолнце\nзвезды | uniq
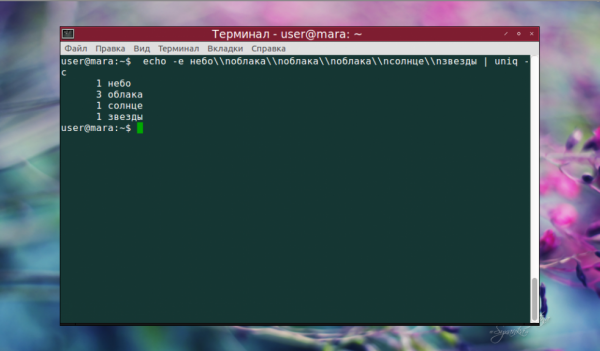
После команды uniq можно использовать её опции. Вот пример вывода, где не просто удалены повторы, но и указано количество одинаковых строк:
echo -e небо\nоблака\nоблака\nоблака\nсолнце\nзвезды | uniq -c
Теперь применим команду к тексту, который находится в файле.
uniq --all-repeated=prepend text-example.txt
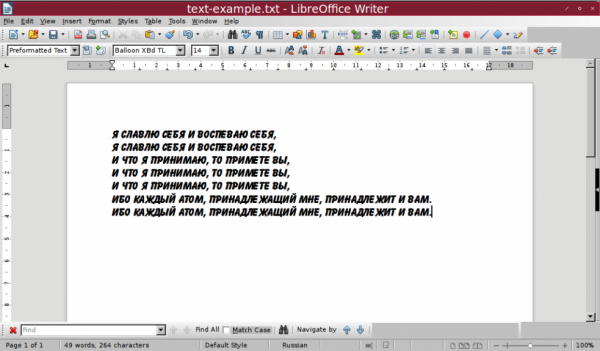
Как можно заметить, глядя на снимок экрана, команда вывела в качестве повторяющихся только вторую и третью группу строк.
Причина этого — незаметный глазу символ пробела, который стоит в конце одной из строк первой группы. Нужно быть предельно внимательным при использовании uniq, чтобы получить качественный результат.
Используемая опция —all-repeated=prepend выполнила свою работу — добавила пустые строки в начало, в конец и между группами строк. Теперь попробуем сравнить только первые 5 символов в каждой строке.
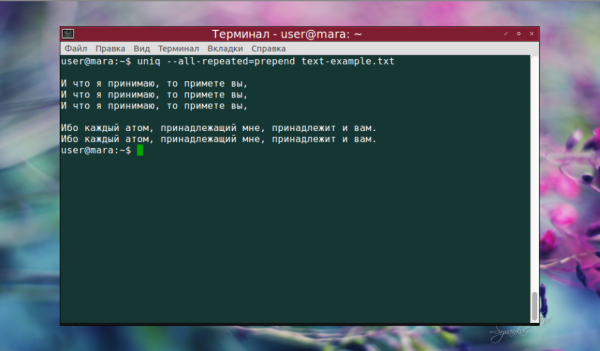
echo -e небо исполосовано молниями\nоблака на небе\nоблака разогнал ветер\nоблака закрыли солнце\nсолнце светит ярко\nзвезды кажутся огромными | uniq -w5
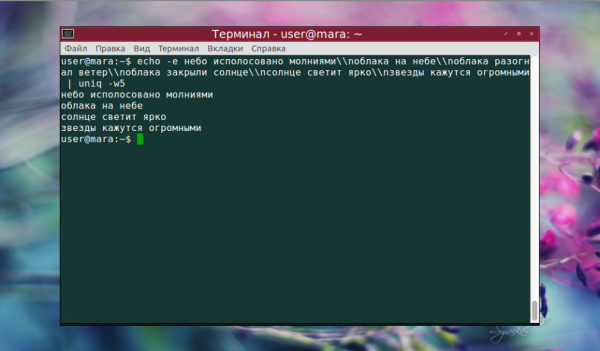
Как видно на скриншоте, повторяющиеся строки, которые начинались словом «облака», были удалены. Осталась только первая из них. Вывод только уникальных строк с использованием опции -u выглядит так:
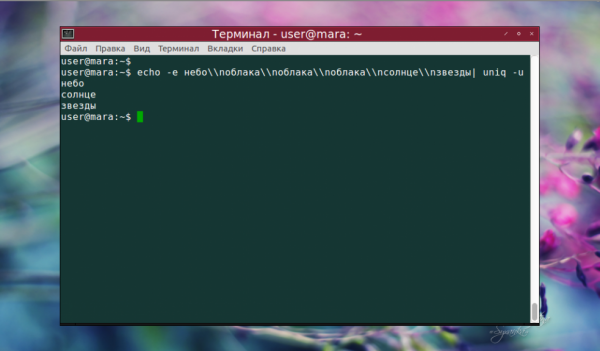
echo -e небо\nоблака\nоблака\nоблака\nсолнце\nзвезды | uniq -u
Чтобы проигнорировать определенное количество символов в начале одинаковых строк, воспользуемся опцией —skip-chars. В данном случае команда пропустит слово «облака», сравнив слова «перистые» и «белые».
echo -e небо\nоблака перистые\nоблака перистые\nоблака белые\nсолнце\nзвезды | uniq --skip-chars=6
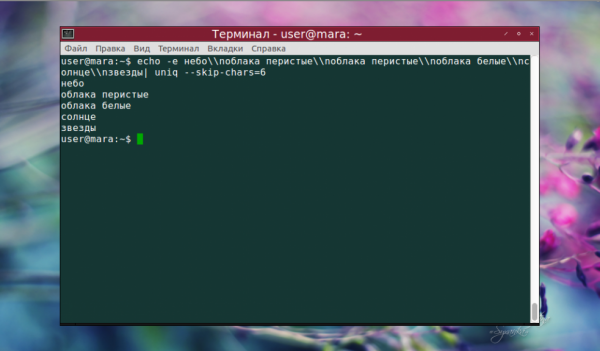
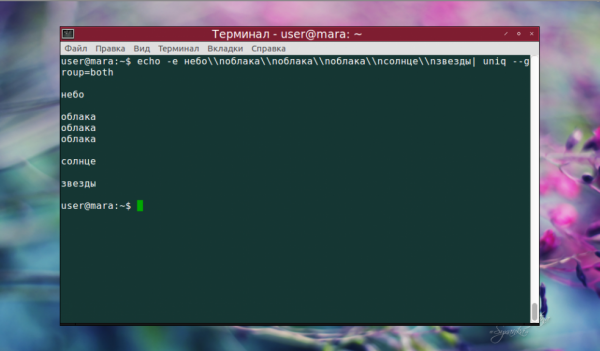
А вот наглядная демонстрация отличий при использовании опции —group с разными значениями. both добавило пустые строки как перед текстом, так и после него, а также между группами строк.
echo -e небо\nоблака\nоблака\nоблака\nсолнце\nзвезды | uniq --group=both
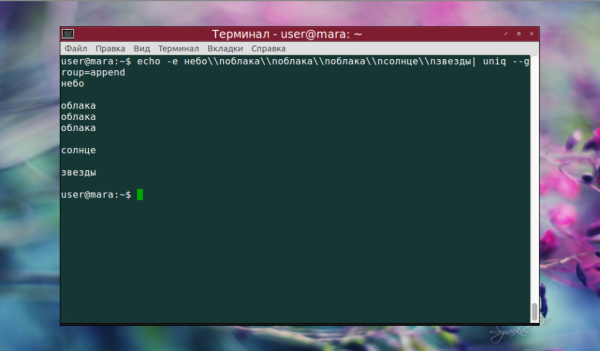
Тогда как append не добавило пустую строку перед текстом:
echo -e небо\nоблака\nоблака\nоблака\nсолнце\nзвезды | uniq --group=append
Выводы
Команда uniq linux пригодится тем, кто часто и много работает с массивами текста, не имея возможности вычитывать их самостоятельно. Следует заметить, что не все версии uniq работают исправно, поэтому иногда результат выдачи может отличаться от ожидаемого.
Свои вопросы относительно использования команды, а также замечания и пожелания оставляйте в комментариях.